客户端/服务器端通信协议
使用半双工的通信方式。使用的是无控制流的协议。
查询线程的状态
- Sleep:线程等待客户端发请求
- Query:正在执行查询语句或者返回结果给客户端
- Locked:等待锁(表锁或者行锁)
- Analyzing and statistics:搜集存储引擎的统计信息,生成查询计划
- Copying to tmp table(on disk):正在执行查询,并且将结果集复制到一个临时表。这状态一般是GROUP BY、文件排序或者是UNION操作。如果后面有on disk则表示正在对临时表进行持久化操作
- Sorting result:线程正在对表进行排序
- Sending data:可能为线程在多个状态传送数据或者生成结果集,或者向客户端返回结果集
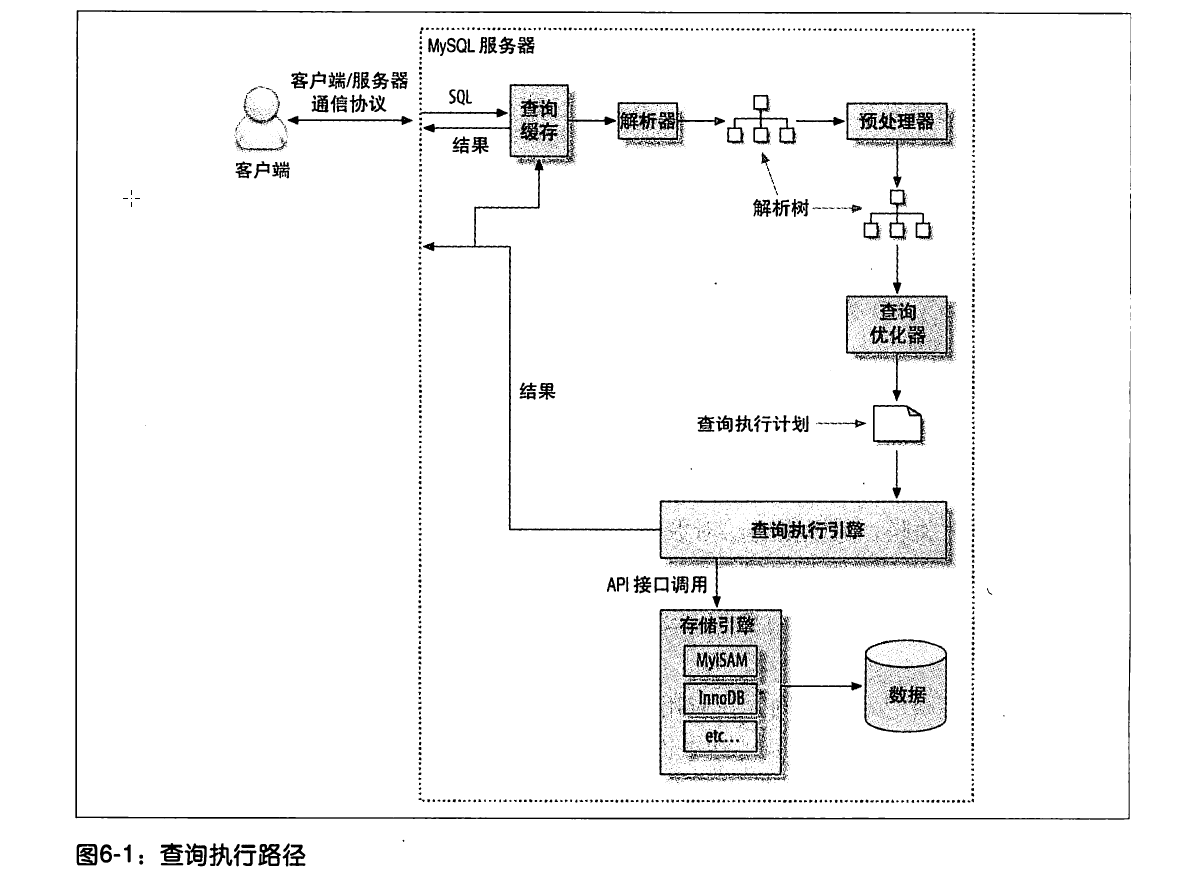
查询优化处理
包括:
解析SQL
对SQL进行解析,并生成解析树。校验是否使用错误的关键字或者关键字的顺序是否一致。
预处理
校验解析树是否合法。检验数据表和数据是否存在。解析名字和别名,判断是否有歧义
查询优化器
一条执行语句可以有多重执行方式,最后都返回同样的结果。优化器的作用就是找出最好的一种。
MySQL使用的是基于成本的优化器。成本的单位使用一个随机读取4字节的页数来表示。数值是基于每个表或者是索引的页数、索引的基数、索引和数据行的长度和分布情况等统计信息来估计的。在计算的时候并不考虑缓存,假设读取任何数据都需要一次磁盘IO。
查询优化器在服务器层,但是没有保存数据和索引的统计信息。统计信息是存储引擎提供给优化器的,因此如何统计是有存储引擎实现的
MySQL优化器选择错误的执行计划的原因
- 统计信息不准确
- 执行计划的成本不等于实际执行的成本
- MySQL的最优是成本的最优,而不是时间的最优
- MySQL不考虑并发执行的查询
- 不总是基于成本优化。如使用MATCH()子句,则存在全文索引的时候就会使用全文索引
- 不考虑不受其控制的操作,如执行存储过程和用户自定义函数
优化策略
静态优化
对解析树进行分析并优化。类似于编译时优化
动态优化
动态优化和查询上下文有关。在每次查询时都要重新评估。类似于运行时优化
MySQL能够处理的优化类型
重新定义关联表的顺序
将外连接转换为内连接
使用等价变换规则
对COUNT,MIN和MAX进行优化
如找某一列的最小值,则只需要查询对应的B树索引最左端的记录
预估并转化为常量表达式
如知道一个表达式可以转化为常数时,就会一直把该表达式转化为常数
覆盖索引扫描
子查询优化
提前终止查询
当发现一个不成立的条件,就可以立刻返回空结果。使用LIMIT子句直接返回结果
等值传播
列表IN()的比较
关联查询优化
MySQL执行关联的策略
任何关联都执行嵌套循环关联操作。
MySQL会先从一个表中循环去取单条数据,然后嵌套循环到下一个表中寻找匹配的行。然后根据各个表匹配的行,返回查询需要的各个列。MySQL会尝试在最优一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行,就会返回到上一层次关联表。以此类推迭代执行。通俗来讲就是for循环嵌套。
关联查询不一定是要查询两张表。每一个子查询或者是每一个select的结果都会产生一张表
优化
通过评估不同顺序时的成本来选择一个代价最小的关联顺序。
当关联的表的数量超过optimizer_search_depth的值时,优化器就会使用贪婪搜索的方式查找最优的关联顺序
排序优化
两种排序算法
两次传输排序
首先读取行指针和需要排序的字段,然后对其排序。再根据排序结果读取所需要的数据行。缺点是两次IO操作。优点是节省内存
单次传输排序
读取查询所需要的所有列,然后再根据给定列进行排序,最后直接返回排序结果。优缺点与两次传输排序相反
优化器的缺陷
- MySQL的子查询实现得非常糟糕。where中包含IN()的子查询。一般会优先执行IN()。但是MySQL可能会将外层表压到子查询当中。可以用exist函数改写。
- MySQL无法将限制条件从外层下推到内层
- 无法利用多核特性来并行执行查询
- 不支持hash关联
- 不支持松散索引扫描。如索引(a,b)。不支持直接使用b进行扫描
- 如果没有索引,使用MIN和MAX会进行一次全表扫描。可以使用limit1代替
- 不能再同一个表上查询和更新。可以通过生成表的方式解决



