Elasticsearch 集群
特点
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的
写流程
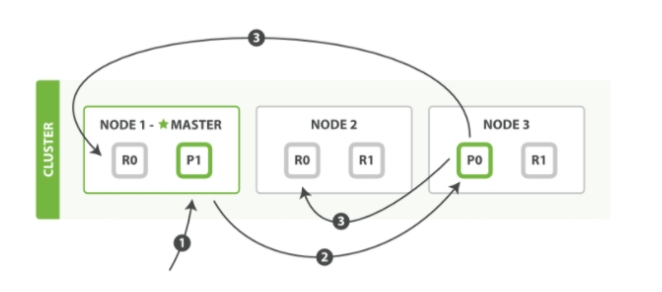
(P0为主分片,R0为P0的副本分片)
- 客户端向 Node 1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的
主分片目前被分配在 Node 3 上。 - Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
读流程
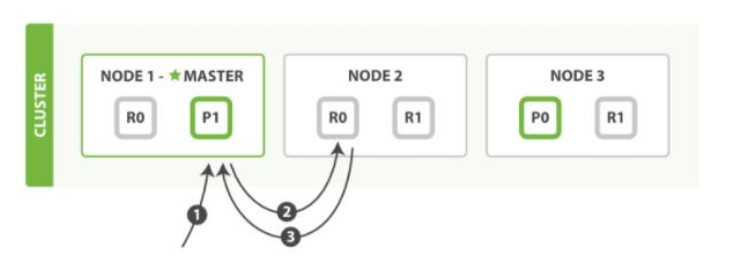
- 客户端向 Node 1 发送获取请求。
- 节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个
节点上。 在这种情况下,它将请求转发到 Node 2 。 - Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端
更新流程
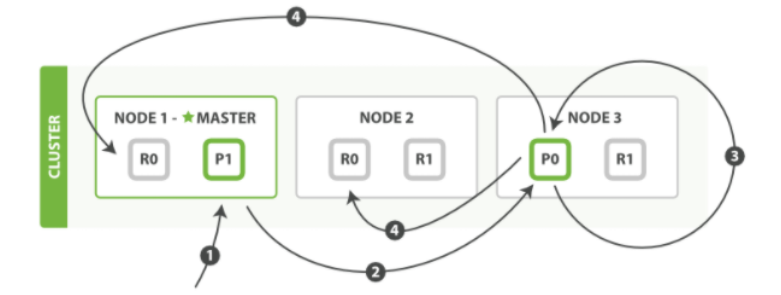
- 客户端向 Node 1 发送更新请求。
- 它将请求转发到主分片所在的 Node 3 。
- Node 3 从主分片检索文档,修改 _source 字段中的 JSON ,并且尝试重新索引主分片
的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过 retry_on_conflict 次
后放弃。 - 如果 Node 3 成功地更新文档,它将新版本的文档并行转发到 Node 1 和 Node 2 上的
副本分片,重新建立索引。一旦所有副本分片都返回成功, Node 3 向协调节点也返回
成功,协调节点向客户端返回成功。
更新/添加写入disk的过程
Elasticsearch 基于 Lucene, 这个 java 库引入了按段搜索的概念。
按段搜索会以如下流程执行:
- 新文档被收集到内存索引缓存
- 不时地, 缓存被提交
- 一个新的段:一个追加的倒排索引被写入磁盘。
- 一个新的包含新段名字的 提交点 被写入磁盘
- 磁盘进行 同步 — 所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件
- 新的段被开启,让它包含的文档可见以被搜索
- 内存缓存被清空,等待接收新的文档
这种按段搜索就会因为磁盘写入的速度过慢成为性能瓶颈。因此引入了磁盘缓存加快这一过程。只要文件已经在缓存中,就可以像其它文件一样被打开和读取了。
提交(Commiting)一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。 但是 fsync 操作代价很大; 如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着 fsync 要从整个过程中被移除。在 Elasticsearch 和磁盘之间是文件系统缓存。 像之前描述的一样, 在内存索引缓冲区中的文档会被写入到一个新的段中。 但是这里新段会被先写入到文件系统缓存—这一步代价会比较低,稍后再被刷新到磁盘—这一步代价比较高。
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
日志
每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确
保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。 Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。
执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush
分片每 30 分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新
流程:
- 一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了 translog
- 刷新(refresh)使分片每秒被刷新(refresh)一次:
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行 fsync 操作。
- 这个段被打开,使其可被搜索
- 内存缓冲区被清空
- 这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志
- 每隔一段时间—例如 translog 变得越来越大—索引被刷新(flush);一个新的 translog被创建,并且一个全量提交被执行。
- 所有在内存缓冲区的文档都被写入一个新的段。
- 缓冲区被清空。
- 一个提交点被写入硬盘。
- 文件系统缓存通过 fsync 被刷新(flush)。
- 老的 translog 被删除。


